MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents
Feb 15, 2025· ,,,,,,,,,·
0 min read
,,,,,,,,,·
0 min read
Kunlun Zhu
Hongyi Du
Zhaochen Hong
Xiaocheng Yang
Shuyi Guo
Zhe Wang
Zhenhailong Wang
Cheng Qian
Xiangru Tang
Heng Ji
Jiaxuan You
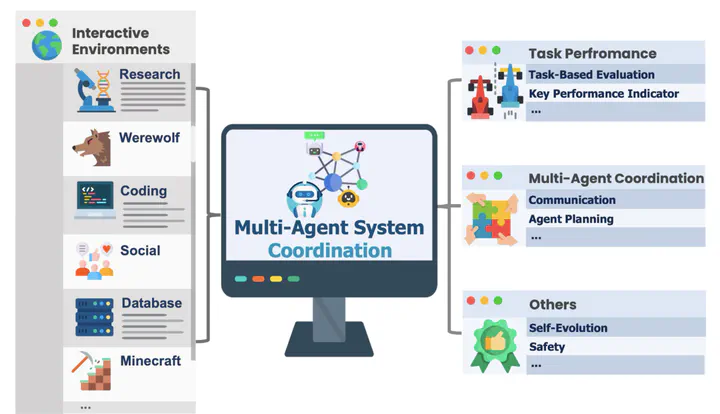 Image credit: Unsplash
Image credit: UnsplashAbstract
Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%.
Type
Publication
In ACL 2025 Main Conference